How I Think About Knowledge in Finance
Finance spent 20 years industrializing its data and almost no time on its knowledge. Then AI changed the economics overnight. Drawing on my years as a practitioner, here is my framework.
Early in my career, I owned the data room for a client (a major Korean conglomerate) selling a stake to a private equity firm. Due diligence was people and time, measured in the hourly rates of corporate attorneys, accountants, and investment bankers. The buy-side law firm sent request lists, and I worked them by hand, finding the contract, the board minute, the clause that settled each question, then deciding what the buyer was cleared to see before it crossed into the room. That last call stayed with me: you can hold material information and still be barred from acting on it.
Howard Marks took me back into that data room during his private credit lecture at Columbia Business School this year. He kept returning to the value private investing overlooks: not the record everyone can read, but the reasoning that produced it (discussed in more detail below). Looking back on that stake sale, the deal almost never turned on the volume of what we handed over; it turned on a handful of facts, and on the one thing the room rarely held: why management had decided what they decided. The contract said what was agreed; the financials, what happened. The reasoning behind both lived in people’s heads and in email threads no one had filed.
I was a human retrieval system for someone else’s high-stakes judgment. I now build the machines that do that work: retrieval and knowledge-graph systems that put AI on top of a firm’s own knowledge. Having lived both sides of this transition, here is my framework for knowledge in finance under AI, in the order that matters: data, the value that makes it a moat, the constraints that decide whether it can be trusted, and the stakeholders who decide everything else.
Knowledge Is the Asset Class Finance Never Industrialized
Banks industrialized data. Golden sources, lineage, catalogs, master data. They did it because they were forced to: after the financial crisis, BCBS 239 made traceable, accurate, complete risk data a supervisory requirement, and as of the most recent assessment only a small minority of the world’s roughly 31 systemically important banks were judged fully compliant. Platforms like Fusion by J.P. Morgan are the visible result: take custody, accounting, and vendor data, harmonize it into one common semantic model, and deliver it into Snowflake, Databricks, and notebooks. Data, industrialized.
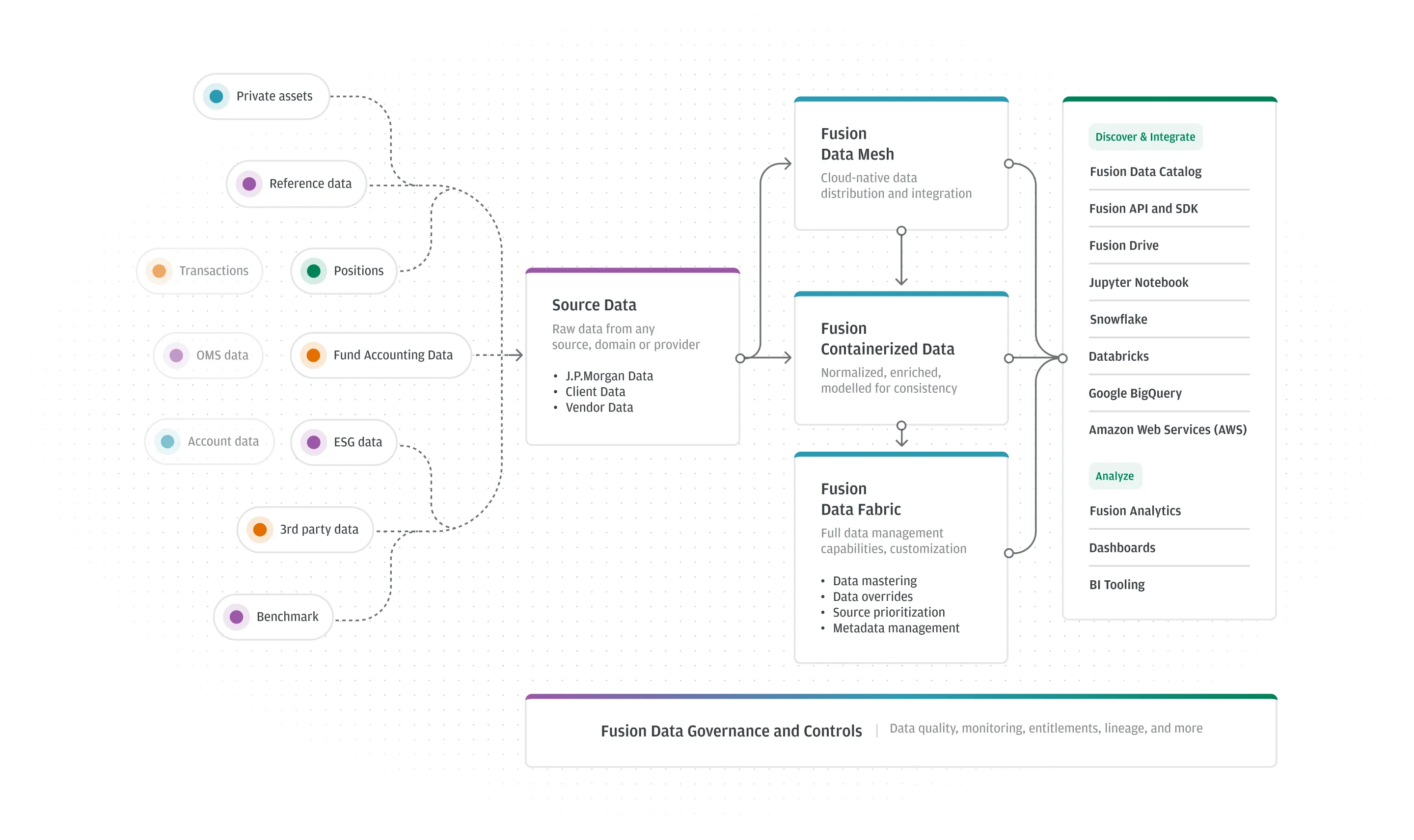
Fusion in one view: any source, normalized into a single model, delivered into the client's own stack. Adapted from J.P. Morgan's Fusion architecture.
Knowledge stayed feral. It sat in heads, decks, mailboxes, and shared drives. Nobody industrialized it because the extraction cost was prohibitive. It was the same cost I had been paying by hand in that data room, scaled to an entire firm: a human had to read each document and decide what it meant. LLMs collapsed that cost to near zero. The moment latent knowledge became cheap to extract, it became an asset class. And an unmanaged asset class, at the scale of a global bank, is simultaneously the largest opportunity and the largest liability on the table. Knowledge management stops being a librarian’s job and becomes a balance-sheet conversation.
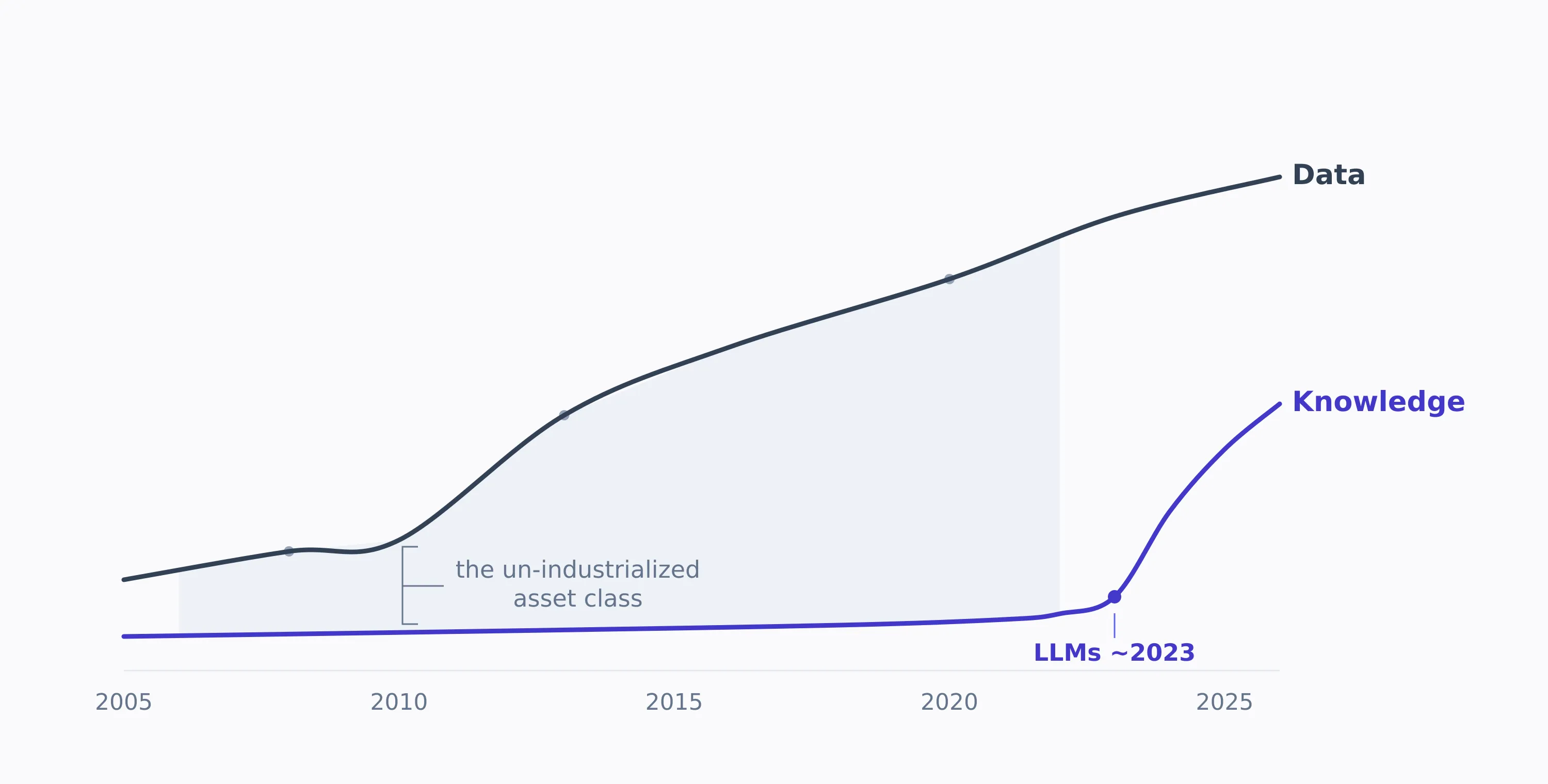
Finance industrialized its data over twenty years. Knowledge stayed feral until the extraction cost collapsed.
I. Data: Three Tiers, and the Valuable One Is the One Nobody Captures
Not all knowledge is the same, and its value is inverted from the effort it takes to capture.
| Tier | What it is | Where it lives | How well it’s managed | Relative value |
|---|---|---|---|---|
| Codified | Documents, research, policies, contracts, filings | Document stores, the data room | Half-managed already | Baseline |
| Embedded | Decisions, and the rationale behind them | Tickets, PRs, threads, meeting notes, deal memos | Barely captured | Highest |
| Tacit | Judgment, pattern recognition, relationships | People’s heads | Not captured by tools at all | Situational |
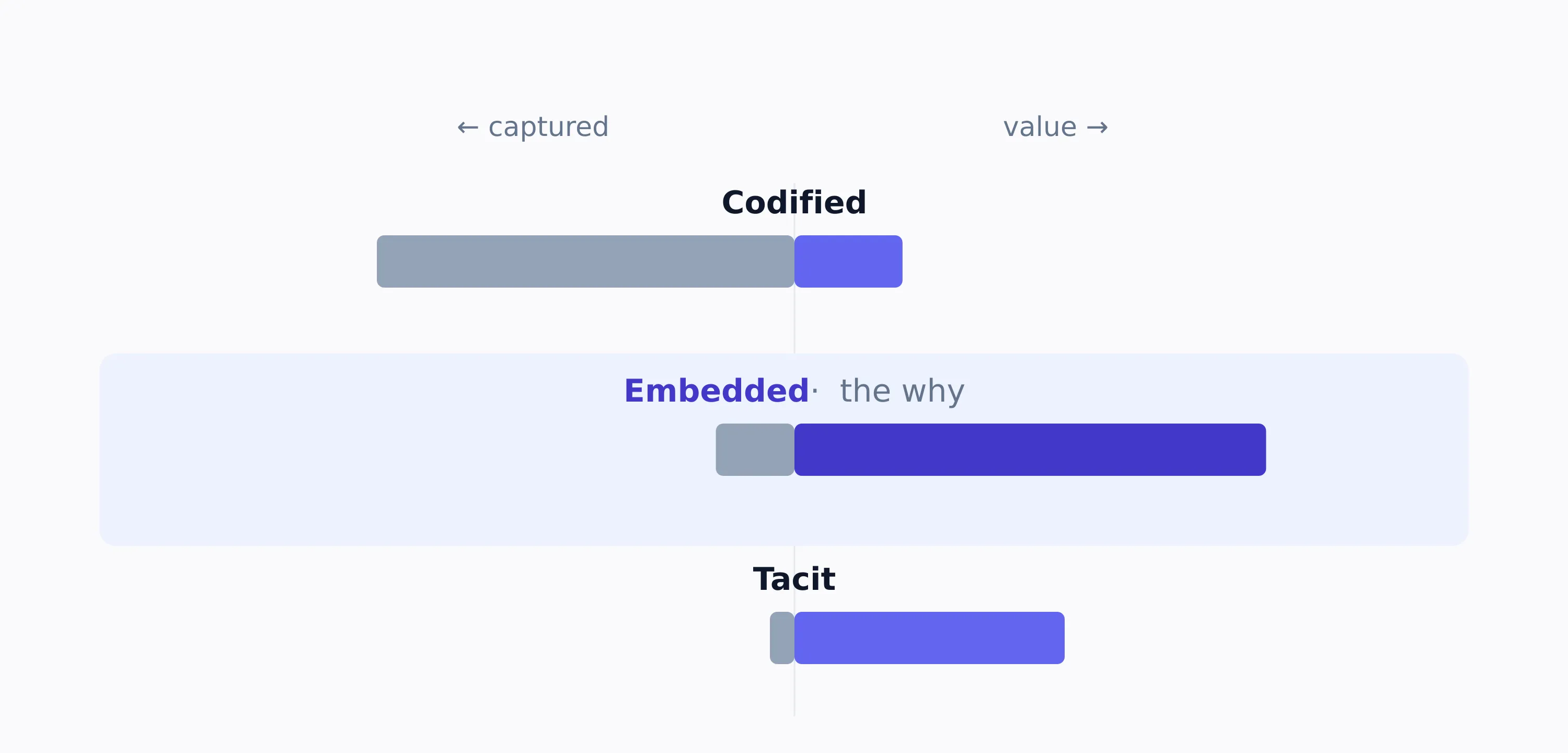
Value runs opposite to capture. The embedded why is the highest-value tier and the least captured.
The contract says what was agreed. The thread says why. The next person making a decision needs the why, and the why is exactly what no system holds. In the data room, the embedded layer was the gap I kept hitting. I could find every number. I could almost never find the reasoning that produced it.
The discipline to fix this already exists. It just got applied to data first. Zhamak Dehghani’s data mesh named the four principles in 2020: domain ownership, data as a product, a self-serve platform, federated computational governance. Knowledge is the same supply chain. Producers, refinement, distribution, consumers. It needs the same product discipline: named ownership, quality metrics, freshness SLAs, provenance, entitlements, and a clean consumption interface.
One thing about the consumer has changed, and it quietly resets the entire design. The consumer of knowledge is increasingly an agent calling an API, not a human browsing a portal. Build for machine consumption (structured, atomic, traceable) and humans benefit as a side effect. Build for humans first and machines get nothing they can use.
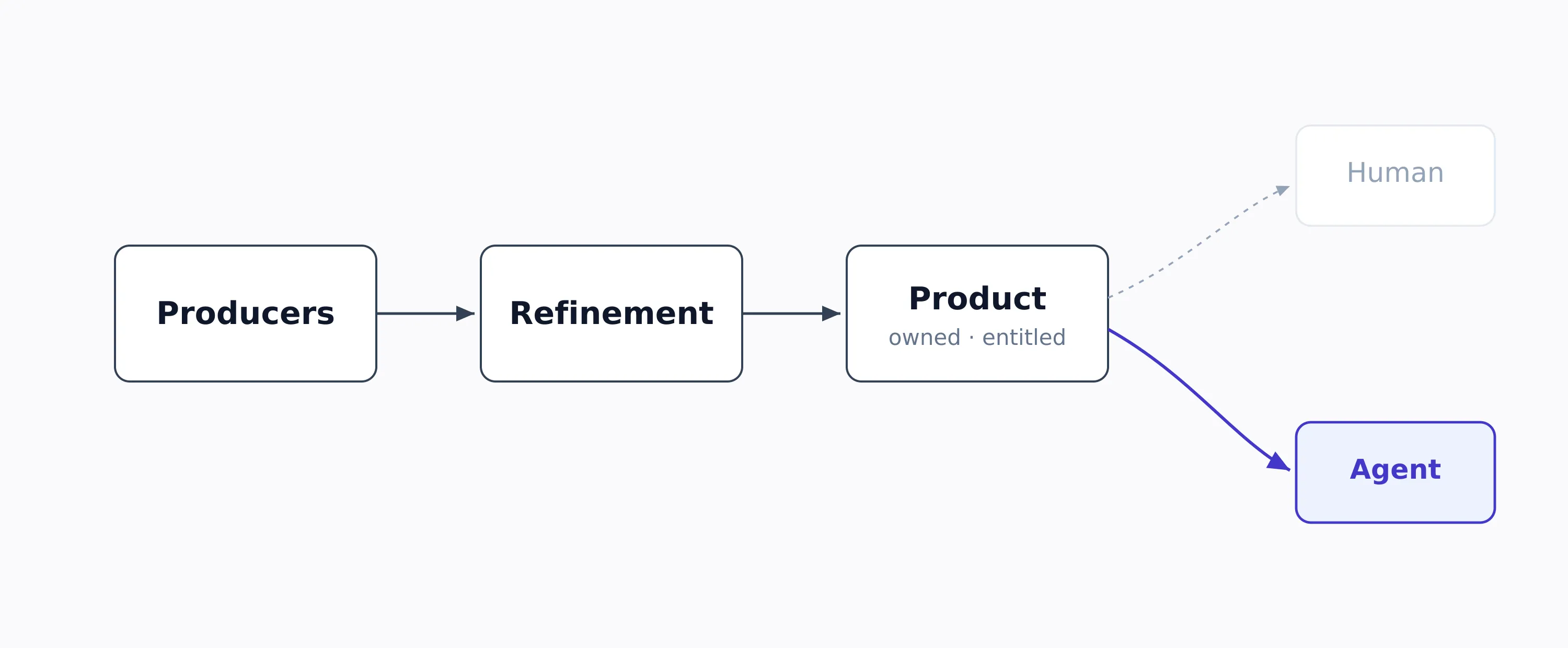
Run knowledge like a data product — owned, measured, entitled — and design for the consumer that now matters most: an agent calling an API.
II. Value: The Model Is the Commodity, the Knowledge Is the Moat
Every firm can buy the same model. None can buy a hundred years of its own deal history, research, post-mortems, and client context. So the competitive question is not which model you license. It is who feeds their model the highest-quality proprietary knowledge, fastest and safest. That sentence is what “make data AI ready” actually means.
Marks’s CBS lecture is where it got concrete for me. He built Oaktree into one of the world’s largest credit investors, and the striking thing is what the edge was not. In private credit the data is thin and everyone reads the same agreements. The edge was second-level thinking: “a superior ability to figure out what the readily available quantitative information implies,” the judgment about which borrower survives the cycle and which does not.
What stayed with me was his discipline of writing it down. For thirty-five years he has published memos that record not what he decided but why he decided it, and they became essential reading across the industry. Sitting in that room, I realized he had spent a career doing the thing this essay is about, by hand. The data room had taught me the why was the valuable part; Marks made me see it was the defensible part. This essay is the same move: the reasoning, written down before it slips back into people’s heads.
His definition of the machine, that day, was deflating: “a nerd that has read everything that’s ever been written, remembers it, and can find it right away.” It can read every credit agreement in a portfolio in minutes. What it cannot do is sit down with five CEOs and figure out which one is Steve Jobs. In private markets especially, the moat was never the documents. It was the reasoning almost no one bothered to write down.
An LLM can read every agreement in minutes — that's first-level. The moat is the second-level judgment about what they mean.
If knowledge is an asset now, the discipline that applies to it is valuation: pricing it by the cash flows and the risks attached. Once knowledge became cheap to extract, it crossed the line from cost center to asset: it has a value (better, faster, more defensible decisions) and a risk (leakage, staleness, a wrong answer acted on). The firms that will pull ahead are the ones that start treating it on those terms, with the same rigor they already apply to a security.
Value being inverted from effort has a commercial consequence too: don’t boil the ocean. Structure is expensive. Ontologies and knowledge graphs cost real money to build and maintain, so you apply them where connected knowledge demonstrably beats flat retrieval, not everywhere by default. The skill is knowing which questions actually require the graph and which are fine with a document and a citation.
III. Constraints: In Finance, the Constraints Are the Architecture
Generic knowledge management treats compliance as friction to route around. In finance it is the opposite. The constraints are load-bearing, and three of them shape every real design decision.

In finance the constraints are the architecture. Each is a load-bearing layer, anchored to a rule — and the eval layer is the one holding weight now.
Access is not uniform. The same question must return different answers depending on who asks. This is not a product preference; it is the law. I first learned it by hand in that data room, and it is written into the CFA Code I was tested on: a charterholder cannot act on material nonpublic information, and firms must “enact a firewall to restrict the flow of proprietary information.” Information barriers and the Advisers Act’s prohibition on misusing nonpublic information mean entitlements have to be enforced at query time and inherited from the source, never bolted on afterward. A knowledge system that can leak across a wall does not have a quality problem. It has an incident.
Nothing unattributable is actionable. A synthesized answer with no provenance is a regulatory event waiting to happen. In diligence, a number that did not trace to a source document did not go in the model, full stop. The same rule now governs AI output: S&P’s Document Intelligence sells “precise citations for full auditability,” and FactSet’s assistant sells “auditable answers.” Citation is not UX polish. It is what makes the answer usable at all, and SEC Rule 17a-4, enforced with over $600 million in penalties across 70-plus institutions in fiscal 2024 alone, is the reason keeping a record of that output is not optional.
Knowledge decays and contradicts itself. At a few hundred thousand employees, the corpus disagrees with itself. In a markets business, knowledge has a shelf life: last quarter’s research view or risk limit can be worse than nothing. The system needs what golden sources gave data: authority tiers (authoritative versus anecdotal), supersession (this policy replaces that one), and valid-from / valid-to dates. Most of what gets called a “RAG quality problem” is unmanaged conflict and staleness wearing a technical costume.
Underneath all three sits a simple rule: if you can’t measure it, you can’t run it. Groundedness, freshness, coverage, retrieval quality, all of it gets an SLO, measured continuously, with an evaluation harness standing guard as the corpus grows. Because trust here is binary.
The third hallucinated answer is the last query that managing director ever runs. You do not get them back.
The regulatory frame is still catching up to this. OCC Bulletin 2026-13 explicitly places generative and agentic AI outside the established model-risk guidance, which means for now the eval harness is the only guardrail that is actually load-bearing. The firms that understand that are building it first.
IV. Stakeholders: The Part That Actually Decides It
Everything above is necessary. None of it is sufficient. I have seen well-architected systems fail and plainer ones win, and the difference was never the architecture. It was whether the people on either end of the pipe had a reason to use it. Knowledge systems are won and lost on stakeholders.
| Stakeholder | What they actually need | What fails if you ignore them |
|---|---|---|
| The producer (analyst, engineer, PM) | Capture as a byproduct of work, not extra work | The high-value why never gets written down |
| The consumer (increasingly an agent) | Structured, atomic, traceable, entitlement-aware data | Human-first design that machines can’t consume |
| The gatekeeper (compliance, the barrier) | Enforcement at query time, inherited from source | A leak, which is to say an incident |
| The skeptic with authority (the MD) | Answers correct enough to trust by the third try | One bad answer and the user base evaporates |
| The underserved adopter (a smaller desk, another region) | A real, sharp problem visibly solved | You boil the ocean and prove nothing |
| The agent (the new labor) | Knowledge as instructions, guardrails, and audit trail | Autonomous work with no control plane |
A few of these deserve more than a row.
Producers. The highest-value knowledge, the why, only gets captured if writing it down is a byproduct of doing the work. You cannot extract tacit knowledge with a tool. You change the workflow so the artifact falls out of it. Software engineering solved this culturally long before anyone called it knowledge management: the commit message, the pull request, the design doc are all the why, captured as a side effect of shipping. That is why coding agents are the cleanest reference model for where this is heading.
The underserved adopter. Adoption follows pain, not the org chart. The instinct is to start with the biggest line of business. The better move is to start with the group whose pain is sharpest and whose alternatives are worst, often a smaller team or a different region that technology has underserved. They adopt fastest, prove the value, and create the pull that the marquee desks will never give you on faith.
The agent as a stakeholder. Today, knowledge systems retrieve: a human asks, the system answers. Next, agents act on knowledge, and the knowledge base becomes their operating instructions, their guardrails, and their audit trail. JPMorgan put an internal LLM assistant in front of roughly 200,000 employees within months. On the supply side, the late-2025 convergence on Model Context Protocol servers sends the same signal: Snowflake, LSEG, Morningstar and PitchBook, and Arcesium all shipped one inside a single quarter. The consumer of financial data stopped being only human. The firm whose knowledge is structured, entitled, fresh, and evaluated is the one that can deploy that new labor safely at scale first.
The throughline. Here is what owning that data room taught me, and what I keep coming back to: the deliverable was never the pile of documents I assembled. It was whether the people on the other side of the deal could reach a decision they could defend to their own investment committee. A document nobody could trust or trace was worth nothing to them, however neatly it was filed. Knowledge systems are the same. The deliverable is never the retrieval. It is a defensible action that a specific, accountable person — or now, a specific agent — can stand behind. That is why stakeholders come last on the list and first in importance.
Where This Goes
I started my career between the data and the decision, running the room that one side disclosed and the other had to act on. The work has moved up a layer. The question is no longer how one sponsor reads one data room. It is how a firm turns a century of its own feral knowledge into something an agent can act on and a regulator can audit.
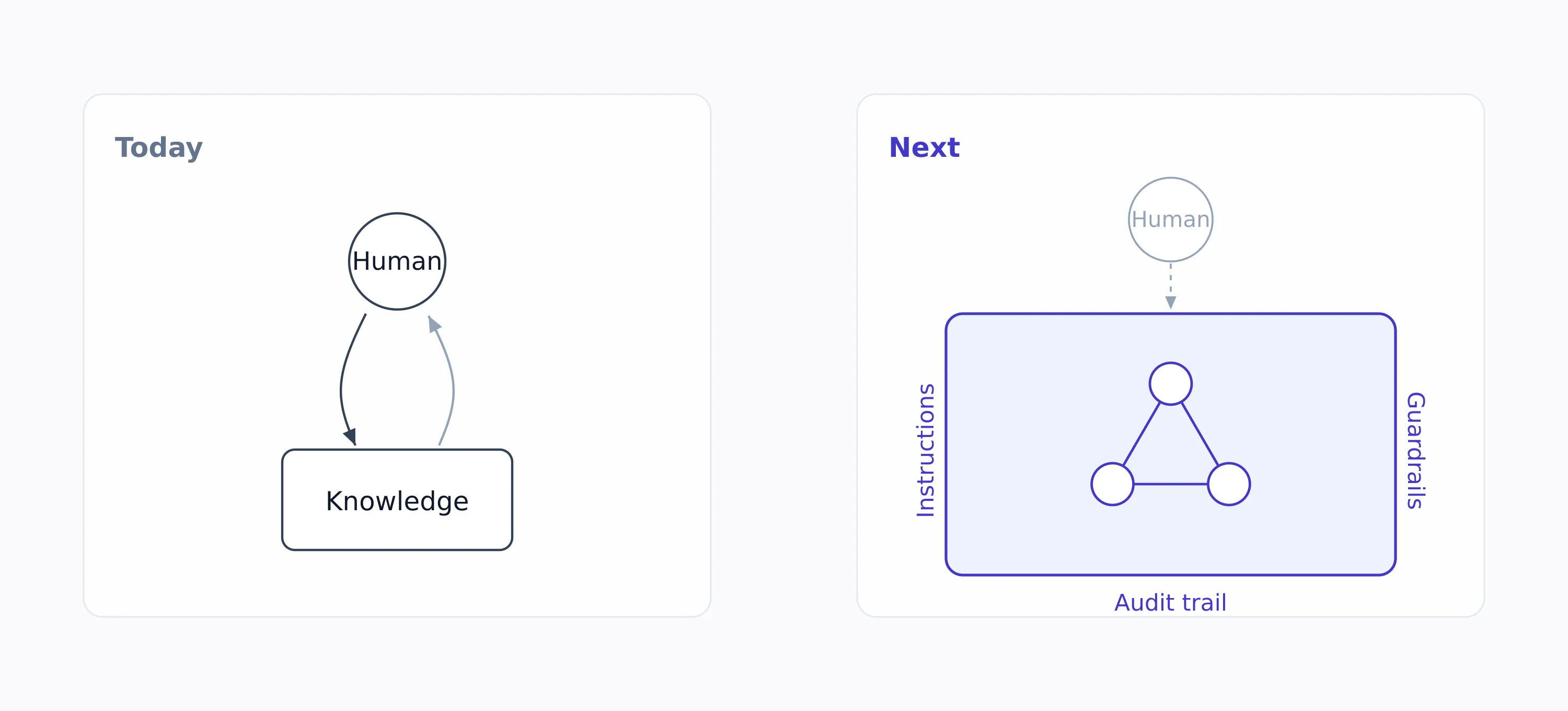
Today, knowledge answers questions. Next, it becomes the control plane an agent acts inside — instructions, guardrails, and audit trail.
The firms that win this will not be the ones with the best model. Everyone has the same model. They will be the ones whose knowledge was trustworthy enough — structured, entitled, fresh, and measured — to hand to an agent and defend every action it takes. That is the asset finance never got around to industrializing. It is buildable now. And I think it is the most interesting thing in the industry.